
Table of Contents
Inclusion and ethics statement
Data informing the GDD modeling estimates for this study, including from LMICs (low- and middle-income countries), were collected between 1980 and 2018 from GDD consortium members and publicly available sources in the form of dietary intake surveys. If nationally representative surveys were not available for a country, we also considered national surveys without representative sampling, followed by regional, urban or rural surveys, and finally large local cohorts, provided that selection and measurement biases were not apparent limitations (for example, excluding studies focused on a selected population with a specific disease, a certain profession or following a particular dietary pattern). For countries with no surveys identified, other sources of potential data were considered, including the WHO Infobase, the STEP database and household budget survey data. As of August 2021, we identified and retrieved 1,634 eligible survey years of data from public and private sources. Of these, 1,224 were checked, standardized and included in the GDD model, including 450 surveys informing SSB intake estimates12.
Most surveys identified were privately held or, if public, not available in relevant format for GDD modeling (for example, not jointly stratified by age, sex, education, and urban or rural status). We thus relied almost entirely on direct consortium member contacts for each survey to provide us with exposure data directly. Roles and responsibilities of GDD consortium members were determined and agreed upon before data sharing as part of a standardized data sharing agreement. The draft manuscript was shared with all GDD consortium members before submission for peer review, and all members are included as coauthors of this work. We endorse the Nature Portfolio journals’ guidance on LMIC authorship and inclusion and are committed to the inclusion of researchers from LMICs in publications from the GDD. We share the GDD data with the entire consortium, encourage authors from LMICs to take the lead on analyses and papers, and can provide technical and writing support to LMIC authors. For more details on the collaborative GDD data collection process, please visit our website at https://www.globaldietarydatabase.org/methods/summary-methods-and-data-collection.
This research is locally relevant to all countries included, given that it disaggregates findings nationally and subnationally by key demographic factors such as age, sex, education level and urbanicity, providing decision-makers with the CVD and diabetes risk associated with SSB intakes over time.
This modeling investigation was exempt from ethical review board approval because it was based on published data and nationally representative, de-identified datasets, without personally identifiable information. Individual surveys underwent ethical review board approval required for the applicable local context.
Study design
A CRA model14 estimated the numbers, proportions and uncertainty of global T2D and CVD incidence, DALYs and mortality attributable to intake of SSBs among adults aged 20+ years. Importantly, the CRA framework does not use ecologic correlations to estimate risk, but incorporates independently derived input parameters and their uncertainties on sociodemographics, population size, risk factor (that is, SSBs) their multivariable-adjusted estimated etiologic effects on disease based on external studies, and background disease incidence, mortality and DALYs14. These parameters are entered into the model to estimate the disease burdens and their uncertainties. Specifically for this investigation, we leveraged input data and corresponding uncertainty in 184 countries including (1) population SSB intake distributions based on individual-level survey data from the GDD (https://www.globaldietarydatabase.org/)7,12,13; (2) optimal SSB intake levels from previous analyses67; (3) direct age-adjusted etiologic effects of SSBs on T2D, ischemic heart disease and ischemic stroke adjusted for BMI2,68,69,70, and of weight gain on T2D15, ischemic heart disease16 and ischemic stroke15 from previous meta-analyses and pooled analyses of prospective cohorts, as well as linear, BMI-stratified effects of SSBs on weight gain or loss17; (4) population overweight (BMI ≥ 25 kg m−2) and underweight (BMI < 18.5 kg m−2) distributions from the (non-communicable disease) NCD Risk Factor Collaboration (NCD-RisC)71; (5) total T2D, ischemic heart disease, and ischemic stroke incidence, DALYs and mortality estimate distributions from the GBD study72,73; and (6) population demographic data from the United Nations Population Division74,75 and the Barro and Lee Educational Attainment Dataset 201376, as previously reported31 (Supplementary Table 7).
Bias and reliability were addressed in each of the independent data sources used in our model. The GDD selected national and subnational dietary surveys without apparent measurement or selection biases7, and leveraged a Bayesian model to incorporate differences in data comparability and sampling uncertainty. In GBD, bias adjustment of underlying rates of T2D and CVD not specifically meeting the gold-standard definition of these causes was done using network meta-regression before estimation in DisMod, while implausible or unspecified causes of death were redistributed to valid underlying causes of death using reclassification algorithms73,77. Etiologic effects were obtained from published meta-analyses or pooled analyses of prospective cohorts and randomized control trials including multivariable adjustment for age, sex, BMI and other risk factors to reduce bias from confounding2,68,69,70. Studies with increased risk of bias such as retrospective or cross-sectional studies were excluded2. Underlying adiposity rates were obtained from the NCD-RisC, which used national or subnational surveys that collected measured height and weight data to avoid bias in self-reported data71.
The GBD study uses a different approach to dietary assessment, primarily relying on adjusted United Nations (UN) and FAO national per capita availability of sugar as primary data to estimate SSBs, with a limited set of individual-level dietary surveys (N = 44). In comparison, the GDD uses a much more comprehensive database of largely individual-level dietary surveys to estimate SSB intake (N = 450), with other data (such as UN FAO sugar) used as covariates rather than as primary data. Thus, in addition to novel stratification by educational level and area of residence, the GDD dietary estimates may be more valid and informative. Our investigation leverages published diet–disease etiologic effects from extensive meta-analyses identified through reviews conducted by our team, includes both direct and BMI-mediated effects, and incorporates new data on prevalence of overweight and obesity from the NCD-RisC. Our study also estimates incident cases, which is not a measure reported in previous global studies.
Compared with our previous 2010 estimates3, our present investigation includes major expansion of individual-level dietary surveys and global coverage through 2018; updated modeling methods, covariates and validation to improve estimates of stratum-specific mean intakes and uncertainty; inclusion of updated dietary and disease data that are jointly stratified subnationally by age, sex, education level, and urban or rural residence; and updated SSB etiologic effect estimates on T2D, ischemic stroke and ischemic heart disease. This present analysis focused on adults aged 20+ years given the low rates of T2D and CVD globally at younger ages.
Global distributions of SSB intakes
The GDD systematically searched for and compiled representative data on individual-level dietary intakes from national surveys and subnational surveys7,12. The final GDD model incorporated 1,224 dietary surveys representing 185 countries from 7 world regions and 99.0% of the global population in 2020. Of these, 450 surveys reported data on SSBs, totaling 2.9 million individuals from 118 countries representing 86.8% of the global population. Most surveys were nationally or subnationally representative (94.2%), collected at the individual level (84.7%), and included estimates in both urban and rural area of residence (61.6%). Further details on characteristics of surveys with data on SSBs, including availability of surveys per world region, are available in Supplementary Table 1. The world region classification used in our study was based on groupings that are likely to have consistent exposures to disease risk and rates of disease outcomes, and this or similar classifications have been previously used by our team and others73. Countries included in each world region are listed in Supplementary Table 2. Global, regional and national estimates among the 30 most populous countries, by population characteristics in 2020, are available in Supplementary Tables 3 and 4.
SSBs were defined as any beverages with added sugars and ≥50 kcal per 8 oz serving, including commercial or homemade beverages, soft drinks, energy drinks, fruit drinks, punch, lemonade and aguas frescas. This definition excluded 100% fruit and vegetable juices, noncaloric artificially sweetened drinks and sweetened milk. All included surveys used this definition. We used an average sugar content per SSB serving, an assumption that probably has little influence on large-scale demographic estimates such as these but could be a problem for more focused local studies. Home-sweetened teas and coffees (which often would have less than 50 kcal per serving) were not explicitly excluded from the SSB definition at the time of data collection, but total tea and coffee intake were separately collected in the dietary surveys and by the GDD as separate variables. Compared with soda and other industrial SSBs, 100% fruit juices and sugar-sweetened milk, coffee and tea have shown inconsistent evidence for health effects, and were therefore excluded from our definition of SSBs2,9. Differences in health effects may relate to additional nutrients in those drinks, such as calcium, vitamin D, fats, and protein in milk, caffeine and polyphenols in coffee and tea, and fiber and vitamins in 100% juice, or to differences in the rapidity of consumption and/or drinking patterns of these beverages. Notably, each of these other beverages is also generally excluded in policy and surveillance efforts around SSBs12. At high intakes, alcoholic beverages have been associated with T2D and CVD in prospective cohorts and genome-wide association studies78,79. However, the effect of alcoholic beverages on T2D and CVD differs from the effect of SSBs on these diseases, and thus, alcohol and SSB should be analyzed separately2,79,80. Moreover, the exclusion of alcoholic beverages ensures comparability across diverse populations, given variations in alcohol consumption due to religious and cultural factors81. Regulatory shortcomings in labeling 100% fruit and vegetable juices may have led to underestimations in SSB intake and attributable burdens for certain populations82,83.
For our present analysis, we updated SSB intake estimates for 2020 using similar methodology as previously reported12, but with updated food availability data released by FAO for 2014–2020 as covariates. Because FAO updated its methodology for these new estimates, the FAO estimates from this period versus their estimates from earlier years are not directly comparable (for example, a ‘step change’ in FAO estimates was noted comparing 2013 versus 2014 data for most countries). To account for this and retain the relative ranking between nations, we calculated a nation-specific adjustment factor for each FAO covariate, based on the ratio of that nation’s 2013 versus 2014 data, and applied this to each nation’s FAO estimates from 2014 to 2020.
A Bayesian model with a nested hierarchical structure (with random effects by country and region) was used to estimate the mean consumption level of SSBs and its statistical uncertainty for each of 264 population strata across 185 countries from 1990 through 2020, incorporating and addressing differences in data comparability and sampling uncertainty12,84. The model then estimated intakes jointly stratified by age (22 age categories from 0 to 6 months through 95+ years), sex (female, male), education (≤6 years of education, >6 years to 12 years, >12 years) and urbanicity (urban, rural). Although this analysis focuses only on adults aged 20+ years, the model used all age data to generate the strata estimates.
Of the 188 countries with survey data, 3 were dropped from the GDD estimation model owing to unavailability of FAO food availability data (Andorra, Democratic People’s Republic of Korea and Somalia), an important covariate in the estimation model. Uncertainty of each stratum-specific estimate was quantified using 4,000 iterations to determine posterior distributions of mean intake jointly by country, year and sociodemographic subgroup. The median intake and the 95% UI for each stratum were computed at the 50th, 2.5th and 97.5th percentiles of the 4,000 draws, respectively.
Global, regional, national and within-country population subgroup intakes of SSBs and their uncertainty were calculated as population-weighted averages using all 4,000 posterior estimates for each of the 264 demographic strata in each country–year. Population weights for each year were derived from the United Nations Population Division74,75, supplemented with data for education and urban or rural status from a previous study85. Intakes were calculated as 8 oz (248 g) servings per week. For our present analysis, GDD SSB estimates were collapsed for adults aged 85+ years using the 4,000 simulations corresponding to the stratum-level intake data derived from the Bayesian model. In this study, regression-based methods were used to estimate the standard deviation corresponding to each estimated, stratum-specific mean from the dietary survey input data. These mean–standard deviation pairs were then used to generate gamma distribution parameters for usual dietary intake as detailed in the following section.
Estimation of gamma parameters for the distribution of usual intake
Dietary intakes cannot be negative, and the usual intake distributions tend to be skewed to the right86,87. Gamma distributions were shown to be more appropriate than normal distributions for SSBs based on the analysis of GDD input data (for example, NHANES data) in a previous study88 and other research on assessment of population dietary intake89,90, as it is nonnegative and includes a wide range of shapes with varying degrees of skewness91. Standard deviation (s.d.) needed to be obtained to construct the gamma distribution of intakes. Parameters for gamma distribution were generated using the mean estimate from the GDD estimation model and the estimated s.d. for the mean estimate from 1,000 simulations.
Standard deviation estimates for the distribution of usual dietary intake
Stratum-level GDD input survey data were used to fit a linear regression of the s.d. of intake on mean intake (both adjusted for total energy). To determine the appropriate transformation of the input data used for fitting the linear regression, scatter plots of energy-adjusted means versus energy-adjusted s.d. were created. Using this approach, we concluded that a natural log transformation for both mean and s.d. was most appropriate. We also explored excluding demographic and health surveys, household surveys and outlier data owing to the potential unreliability of such surveys for estimating s.d., but determined that no one dietary assessment method contributed unevenly to the observed linear trend. Thus, all available data were included, allowing for the largest possible sample size and greatest generalizability. We also investigated whether the log mean and log s.d. relationship differed by world region, but did not find strong evidence for such heterogeneity. A regression model was used for each individual diet factor to calculate the s.d.:
$${Y}_{i}=\,{\beta }_{0}+{\beta }_{1}{x}_{i}+{\varepsilon }_{i}$$
where i refers to each survey stratum, Yi is the natural log of the s.d. of stratum-specific intake, xi is the natural log of the mean of stratum-specific intake and εi is the random error that follows N(0, σ2).
Monte Carlo simulations for generating standard deviation distributions
Estimates for β0 and β1 were used to predict 1,000 ln(s.d.) values corresponding to 1,000 iterations (k) of the predicted mean intake for each population stratum (j) using Monte Carlo simulations.
$${\widehat{Y}}_{{jk}}=\,{\widehat{\beta}}_{0}+{\widehat{\beta}}_{1}{\widehat{X}}_{jk}$$
in which \(\widehat{{X}_{{jk}}}\) is the kth sample draw of the posterior distribution for mean intake for population stratum j. We propagated uncertainty from the model estimates, as well as variation within the sampling data itself, by randomly drawing from a t-distribution with n − 1 degrees of freedom using the following equation:
$$\mathrm{ln}\left(\widehat{{\rm{{s.d.}}}_{{jk}}}\right)=\,{\hat{Y}}_{{jk}}+\,\widehat{{\rm{\sigma }}}\sqrt{1+\left(\frac{1}{n}\right)\times}\, {t}_{k}^{n-1},$$
in which \(\hat{\sigma }\) is the estimate for σ, n is the number of survey strata, \({t}_{k}^{n-1}\) is the kth sample drawn from a t-distribution with n − 1 degrees of freedom and \(\widehat{{s.d.}_{{jk}}}\) is the kth sample draw of the predicted s.d. distribution for population stratum j.
Estimation of gamma parameters for the distribution of usual intake
The posterior distributions for each stratum-specific s.d. were used to generate 1,000 corresponding shape and rate gamma parameters for the distribution of usual intake, a primary input in the CRA model, using the following equations:
$$\widehat{{\rm{Shape}}_{{jk}}}={\left(\frac{\widehat{{X}_{{jk}}}}{\widehat{{\rm{s.d.}}_{{jk}}}}\right)}^{2}$$
$$\widehat{{\rm{Rate}}_{{jk}}}=\,\frac{\widehat{{X}_{{jk}}}}{\widehat{{\rm{s.d.}}_{{jk}}^{2}}}$$
Estimated SSB–disease relationships
The direct risk estimates between SSB intake and T2D, ischemic heart disease and ischemic stroke were obtained from published systematic reviews and evidence grading, based on published meta-analyses of prospective cohort studies and randomized controlled trials including multivariable adjustment for age, sex, BMI and other risk factors to reduce bias from confounding (Supplementary Table 8)2,68,69,70. The methods and results for the review, identification and assessment of evidence for the SSB–disease relationships have been described2,67. Briefly, evidence for each SSB–disease relationship was first evaluated by grading the quality of evidence according to nine different Bradford Hill criteria for causation: strength, consistency, temporality, coherence, specificity, analogy, plausibility, biological gradient and experiment. This evidence grading was completed independently and in duplicate by two expert investigators. Based on these assessments, probable or convincing evidence was determined independently and in duplicate, in accordance with the criteria of the FAO and World Health Organization92 and with consideration of consistency with similar criteria of the World Cancer Research Fund and the American Institute for Cancer Research93. SSBs had at least probable association for direct etiologic effects (BMI independent) on T2D, ischemic heart disease and ischemic stroke risk, as well as on weight gain. See Supplementary Table 9 for further details on the evidence grading criteria and results of this evaluation. All SSB–disease estimates were standardized from the originally reported 250 ml serving size to 8 oz servings (248 g), the unit used in our analysis.
Given that these studies adjusted for BMI, we separately assessed the BMI-mediated effects (BMI change in kg m−2) based on pooled analyses from long-term prospective cohort studies of changes in diet and changes in BMI (Supplementary Table 8)17. Specifically, we used data from three separate prospective cohort studies: the Nurses’ Health Study (1986–2006), involving 50,422 women with 20 years of follow-up; the Nurses’ Health Study II (1991–2003), including 47,898 women with 12 years of follow-up; and the Health Professionals Follow-up Study (1986–2006) with 22,557 men with 20 years of follow-up. Participants included in these analyses were initially free of obesity (that is, BMI < 30 kg m−2) or chronic diseases and had complete baseline data on weight and lifestyle habits. The associations between SSBs and weight gain were estimated separately for overweight and obese (BMI ≥ 25 kg m−2) and non-overweight adults (BMI < 25 kg m−2), given observed effect modification by baseline BMI status17. We used linear regression with robust variance, accounting for within-person repeated measures, to assess the independent relationships between changes in SSB intake and changes in BMI over 4 year periods. Women who became pregnant during follow-up were excluded from the analysis. BMI-mediated effects did not specifically differentiate between overweight and obesity, which could have led to an underestimation in the BMI-mediated effects among adults with obesity.
To examine the BMI-mediated associations, we assessed the impact of differences in BMI on the risk of T2D, ischemic heart disease and ischemic stroke (Supplementary Table 8)15,16. These relationships were obtained from pooled analyses of multiple cohort studies investigating the quantitative effects of BMI on T2D15, ischemic heart disease16 and ischemic stroke15. The risk estimates were transformed from the originally reported 5 kg m−2 to 1 kg m−2.
Heterogeneity in diet–disease relationships using age-specific relative risks
Age-specific relative risks were calculated for each SSB–disease etiologic relationship based on evidence showing decreasing proportional effects of metabolic risk factors on cardiometabolic disease incidence at older ages (for example, due to other competing risk factors)15,67. The age-specific relative risks were calculated based on the age at event and were assumed to have a log-linear age association, although the true age relationship may differ.
To calculate the age at event for each SSB–disease pair, we obtained relevant data from the original studies. This included the average age at baseline in years, the follow-up time in years, the type of follow-up time reported (for example, maximum, median or mean) and the study weight for each study in each meta-analysis (Supplementary Tables 10–12 and Supplementary Data 4). In cases in which the age at baseline was reported as a range rather than as the average, we used the central value to estimate the mean. If follow-up time to events was not reported, we estimated it based on the duration of the study. For studies that reported maximum follow-up time, we estimated the mean time to event as half of the maximum follow-up, and for studies that reported mean or median follow-up times, as two-thirds of the mean or median follow-up. The unweighted mean age at event for each study was calculated by summing the mean age at baseline and the appropriate mean time to event, and the weighted mean age at event for the meta-analysis as the weighted age at event across all studies. In cases in which specific studies were excluded from the meta-analysis owing to limitations in study quality, or when the meta-analysis was conducted for multiple outcomes, the weights were adjusted accordingly. When study weights were not reported, we assigned equal weights to each study when calculating the mean overall age at event.
Given limited evidence of significant effect modification by sex, we incorporated similar proportional effects of risk factors by sex67. In previous research, we evaluated the proportional differences in relative risk for key diet-related cardiometabolic risk factors, including systolic blood pressure, BMI, fasting plasma glucose and total cholesterol, across six 10 year age groups from 25–34 years to 75+ years67. Given similarities across these four risk factors, the mean proportional differences in relative risk across all risk factors were applied to the SSB–disease relative risks. In this study, we disaggregated the mean proportional differences into 14 5 year age groups from 20–24 years to 85+ years. This was achieved by linearly scaling between each 10 year mean proportional difference in log relative risk, anchoring at the calculated mean age at event for each SSB–disease.
We used Monte Carlo simulations to estimate the uncertainty in the age-distributed log relative risk, sampling from the distribution of log relative risk at the age at event. On the basis of 1,000 simulations, we used the 2.5th and 97.5th percentiles to derive the 95% UI.
Global distributions of adiposity
Prevalence of overweight (BMI ≥ 25 kg m−2) and underweight (BMI < 18.5 kg m−2) in each country–year–age–sex–urbanicity stratum and their uncertainty was obtained from the NCD-RisC. The NCD-RisC collected data from 1,820 population-based studies encompassing national, regional and global trends in mean BMI, with measurements of height and weight taken from over 97 million adults71,94. Surveys were excluded if they relied solely on self-report data, focused on specific subsets of the population or involved pregnancy. The NCD-RisC used a Bayesian hierarchical model to estimate age-specific mean BMI and prevalence of overweight and obesity by country, year and sex. The model incorporated data-driven fixed effects to account for differences in BMI by rural and urban area of residence. A Gibbs sampling Markov Chain Monte Carlo algorithm was used to fit the model, producing 5,000 samples of the posterior distributions of the model parameters. These samples were then used to generate posterior distributions of mean BMI and prevalence of overweight and obesity for each stratum. Estimates were age standardized using age weights from the WHO standard population. Weighting was also used at the global, regional and national levels, taking into account the respective age-specific population proportions by country, year and sex. The estimates of mean BMI and overweight and obesity prevalence were presented along with their respective 95% credible intervals, representing the uncertainty around the estimates. To further stratify the NCD-RisC overweight and obesity prevalence estimates by education level and urbanicity, we assumed that the prevalence did not vary across different education levels or between urban and rural residences. In addition, it was assumed that these estimates remained constant between 2016 and 2020 (as NCD-RisC reports only through 2016, but this CRA analysis assesses estimates for 2020), a conservative assumption that probably underestimates the prevalence of overweight and obesity and, thus, SSB-attributable burdens.
Characterization of optimal intake
The optimal intake level of SSBs served as the counterfactual in our CRA modeling analysis, allowing the quantification of impacts of SSBs on disease risk at the population level. We determined the optimal intake level based on probable or convincing evidence for effects of SSBs on cardiometabolic outcomes. The methodology for defining the optimal intake level has been described67. Briefly, it was determined primarily based on disease risk (observed consumption levels associated with lowest disease risk in meta-analyses) with further considerations of feasibility (observed national mean consumption levels in nationally representative surveys worldwide)95,96, and consistency with existing major food-based dietary guidelines97,98. The term ‘optimal intake’ can be considered analytically analogous to what has been referred to as the ‘theoretical minimum risk exposure level’ in other analyses99,100. We prefer the former term as it is more relevant to dietary risks, which can serve as a benchmark for quantifying disease risk, informing dietary guidance and informing policy priorities.
Global distributions of T2D, ischemic heart disease and ischemic stroke
The estimates of underlying cardiometabolic disease burdens at global, regional and national levels were obtained from the GBD 2021. The GBD collected data from censuses, household surveys, civil registration, vital statistics and other relevant records to estimate incidence, prevalence, mortality, years lived with disability (YLDs), years of life lost (YLLs) and DALYs for 371 diseases and injuries73. These estimates were stratified by 204 countries and territories, 23 age groups and sex, yearly from 1990 to 2021. For this analysis, we used GBD estimates of incidence, mortality and DALYs for T2D, ischemic heart disease and ischemic stroke for 1990 and 2020. The GBD defined T2D as fasting plasma glucose greater than or equal to 126 mg dl−1 (7 mmol l−1) or reporting the use of diabetes medication73. Estimated cases of type 1 diabetes were subtracted from the overall diabetes cases at the most stratified level of age, sex, location and year to estimate T2D cases. Ischemic heart disease was estimated in the GBD as the aggregate of myocardial infraction (heart attack), angina (chest pain) or ischemic cardiomyopathy (heart failure due to ischemic heart disease). Ischemic stroke was defined as rapidly developing clinical signs of (usually focal) cerebral function disturbance lasting over 24 h, or leading to death, according to the WHO criterion of sudden occlusion of arteries supplying the brain due to a thrombus101.
GBD mortality estimates were generated using the Cause of Death Ensemble Model framework, which incorporated various models including different sets of covariates testing the predictive validity, and generating cause-specific mortality estimates73,102,103. Cause of Death Ensemble Model estimates were scaled among all causes such that the sum of cause-specific deaths did not exceed all-cause mortality. YLLs were calculated as the product of the number of deaths for each cause by age, sex, location and year times the standard life expectancy. Life expectancy was first decomposed by cause of death, location and year to represent the cause-specific effects on life expectancy102. Then, the sum across age groups was taken to estimate the impact of a given cause on the at-birth life expectancy from 1990 to 2021. Incidence was modeled using DisMod, a meta-regression tool that used epidemiologic data to estimate the occurrence disease within a population and determines whether cases remain prevalent, go into remission or result in death. YLDs were calculated by splitting the prevalence of each cause into mutually exclusive sequela, each defined by a health state; each health state was then weighted by the corresponding disability weight73. Finally, DALYs were calculated as the sum of YLLs and YLDs.
Disaggregation of T2D and CVD burdens by education level and urbanicity
The GBD provides underlying disease estimates at global, regional and national levels for 1990 to 2021, jointly stratified by age and sex. Extensive previous evidence shows that T2D and CVD outcomes vary by educational attainment and urbanicity104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122. We further stratified the 1990 and 2020 GBD estimates by education level (low, medium, high) and area of residency (urban, rural) to examine potential variations in risk within these subpopulations and to align with the demographic and GDD dietary data stratifications available. This approach required assumptions on distributions of disease burdens by these demographic factors and potentially underestimated uncertainty in our results stratified by these factors.
To stratify the GBD estimates, we conducted a search of scientific literature to identify recent meta-analysis, pooled analyses and large surveys evaluating the association between educational attainment and urbanicity with the risk of T2D and CVD. Because we hypothesized that country income level was a potential effect modifier for the relationships of educational attainment and urbanicity with T2D and CVD risk, we further collected and collated risk estimates stratified by country income level. We limited our analysis to studies adjusting only for age and sex, when possible, to avoid the attenuating effects of adjusting for additional covariates104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122.
We conducted fixed-effects meta-analysis of collated effect sizes (associations between education or urbanicity and disease rates), stratified by country income level. Published estimates were standardized to high versus low education level, matched as closely as possible to the GDD definitions (low: 0–6 years of education; high: >12 years of education), as well as to urban versus rural residence. We pooled estimates within studies when (1) multiple estimates were reported for different CVD outcomes, (2) separate estimates were provided for men and women, (3) estimates were reported for different locations (except by country income) or (4) an intermediate category matched our definitions for education level or area of residence. The characteristics of the studies used to calculate the effect estimates, including their original and calculated effect sizes, can be found in Supplementary Data 5 and 6 for education level and area of residence, respectively.
We conducted a separate fixed-effect meta-analysis for the relationship of education or urbanicity to T2D and CVD, stratified by country income level. We distributed the central estimate of our meta-analyzed risk estimate equally for high versus low education, and urban versus rural residence, by taking its square root and inverse square root (Supplementary Table 13). This approach assumed similar differences from high to medium education as from medium to low education. We also explored distributing the central estimate by incorporating information on the actual distance (for example, grade years) from high to medium education and medium to low education, when such information was available. As the results did not appreciably differ, we used the square root and inverse square root approach to maintain consistency across studies, particularly given heterogeneity in categorizations of education levels. The final calculated effect estimates for the association between education level and area of residence with T2D and CVD, by income country level, can be found in Supplementary Table 13.
The T2D, ischemic heart disease and ischemic stroke estimates for each year–country–age–sex stratum (mean and 95% UI) were multiplied by their respective population proportion, education effect and urban effect. This process created six de novo strata with the raw (unscaled) fully proportioned burden estimates and their uncertainty. The global population proportions for each year were derived from the United Nations Population Division75, supplemented with data on education attainment from a previous study76. Finally, to prevent under- or overestimation of the absolute number of T2D, ischemic heart disease and ischemic stroke cases globally, the raw fully proportioned burden estimates were scaled to match the total burden estimate for each stratum. This scaling ensured that the overall burden estimates remained consistent. Supplementary Table 14 provides a fictitious, illustrative example of how 1,000 T2D cases in a single age–sex population stratum (low-income country) in a given year were disaggregated into the 6 finer education–urbanicity strata using the central estimate of the meta-analyzed education and urban effects. The population proportioned only burden estimates is also provided as a comparison. While uncertainty was incorporated in all the modeling parameters, we were unable to include uncertainty in the stratification of T2D and CVD cases by educational attainment and urban or rural residence as rigorous data to do so were not available.
Statistical analysis: CRA analysis
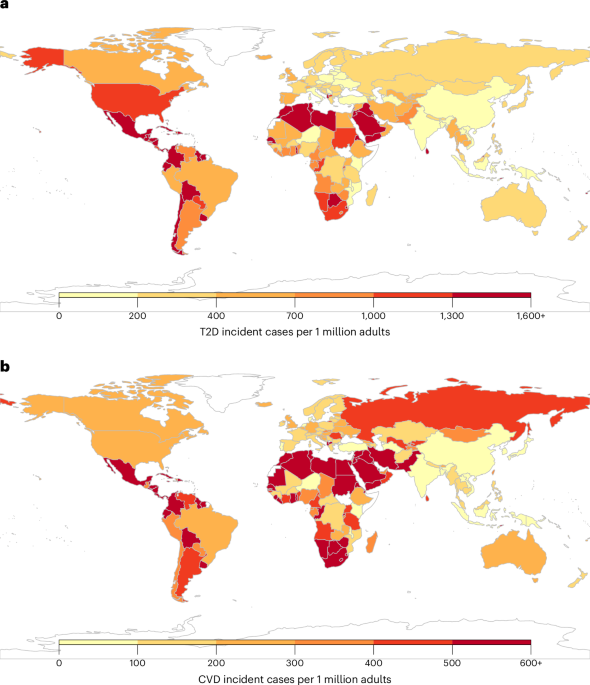
The CRA framework incorporated the data inputs and their uncertainty to estimate the absolute number, rate (per million adults 20+ years) and proportion of T2D, ischemic heart disease and ischemic stroke cases attributable to intake of SSBs in 1990 and 2020 (Supplementary Fig. 18). For each stratum, the model calculated the percentage (population attributable fraction (PAF)) of total T2D, ischemic heart disease and ischemic stroke incidence, mortality and DALYs attributable to intake of SSBs. For BMI-mediated effects, the model considered the associations between observed SSB intakes and changes in BMI at the stratum level. This association was weighted by the prevalence of overweight (BMI ≥ 25), normal weight (BMI >18.5 to <25) and underweight (BMI < 18.5; assumed to have no effect) in each stratum. The resulting weighted BMI change was combined with the relative risk (RR) of BMI change and T2D or CVD using the same continuous PAF formula. Further details on each calculation for the PAF can be found in the sections below.
Given that summing direct and BMI-mediated PAFs would overestimate the combined effect, for each disease stratum (that is, country–year–age–sex–education–residence), the PAF was calculated using proportional multiplication of the direct and BMI-mediated PAFs as follows:
$${\rm{PAF}}=1-\left(\left(1-{\rm{direct}}\; {\rm{PAF}}\right)\times\left(1-{{\text{BMI-mediated}}\, {\text{PAF}}}\right)\right)$$
The resulting PAF was then multiplied by the corresponding number of disease cases to calculate the attributable burden in each stratum. Findings were evaluated globally, regionally and nationally, and by specific population subgroups of age, sex, education and urbanicity. The results are presented as proportional attributable burden (percentage of cases) and attributable rate (per one million adults). This representation of the proportional multiplication for a single risk factor (that is, SSBs) is equivalent to the formula commonly reported for several risk factors: \({\rm{PAF}}=1-\,\mathop{\prod}\nolimits_{i=1}^{n}1-{\rm{PAF}}_{i}\)
Direct-effect PAF
The PAF formula is used to quantify the burden of disease attributable to a particular exposure. It involves comparing the disease cases associated with the observed exposure levels in the population to a counterfactual scenario with an optimal intake distribution, given a known etiologic exposure–disease risk relationship.
In this analysis, we aimed to estimate the burden of incidence, mortality and DALYs for T2D, ischemic heart disease and ischemic stroke attributable to intake of SSBs.
$${\rm{PAF}}=\frac{{\int }_{\!x=0}^{m}{\rm{RR}}\left(x\right)P\left(x\right){dx}-1}{{\int }_{\!x=0}^{m}{\rm{RR}}\left(x\right)P\left(x\right){dx}}\,,$$
The PAF formula used is as follows:
$${\rm{PAF}}=\frac{{\int }_{\!x=0}^{m}{\rm{RR}}\left(x\right)P\left(x\right){dx}-1}{{\int }_{\!x=0}^{m}{\rm{RR}}\left(x\right)P\left(x\right){dx}}\,,$$
where P(x) is the usual SSB intake distribution in a specific population stratum, assumed to follow a gamma distribution as used in previous analyses3,31,88; RR(x) is the age-specific relative risk function for T2D or CVD risk; and m is the maximum exposure level.
RR(x) is defined as:
$$\left\{\begin{array}{cc}\exp (\beta (x-y(x))) & :x-y(x)\ge 0\\ 1 & :x-y(x) < 0\end{array}\right.$$
where β is the stratum-specific change in log relative risk per unit of exposure, x is the current exposure level and y(x) is the optimal exposure level. y(x) is defined to be \({F}_{\rm{optimal}}({F}_{x}^{-1}\left(x\right))\), where Foptimal is the cumulative distribution function of the optimal intake and \({F}_{x}^{-1}\) is the inverse cumulative distribution function of the current exposure distribution. Implicit in how we characterize the relative risk function are certain assumptions, including a linear relationship between the log relative risk (beta) and the unit of exposure. This model assumes that no further risk is associated with exposure beyond the optimal intake level, and that both x and the optimal intake level for an individual at exposure level x are the qth quantile of their respective distributions (the observed exposure distribution and the optimal intake distribution, respectively).
PAF calculation
In practice, simple numerical integration using Riemann sums can be used to compute the integrals in the PAF formula88.
$${\rm{PAF}}=\frac{{\sum }_{i=1}^{n}{P}_{i}({\rm{RR}}_{i}-1)}{{\sum }_{i=1}^{n}{P}_{i}({\rm{RR}}_{i}-1)+1}$$
$${\rm{PAF}}=\frac{{\sum }_{i=1}^{n}{P}_{i}({\rm{RR}}_{i}-1)}{{\sum }_{i=1}^{n}{P}_{i}({\rm{RR}}_{i}-1)+1}$$
n categories are determined by dividing the exposure range (chosen here to be 0, \({F}_{x}^{-1}\left.\left(\varPhi \left(-6\right)\right)\right)\) into 121 intervals, each of length 0.1 when converted to the standard normal scale (except for the first one). Φ is defined as the cumulative distribution function of the standard normal distribution (N(0,1)). More precisely, the range of exposure groups i can be described as:
$$\left({0,\,F}_{x}^{-1}\left(\varPhi \left(-6\right)\right)\right)\,\qquad\qquad:i=1$$
$$\left({F}_{x}^{-1}\left(\varPhi \left(-6+0.1\left(i-2\right)\right)\right),{F}_{x}^{-1}\left(\varPhi \left(-6+0.1\left(i-1\right)\right)\right)\right)\,\qquad:i=1$$
BMI-mediated effects PAF
The association of change in BMI with change in SSB intake was assessed in three pooled US cohorts using multivariate linear regression accounting for within-person repeated measures, as described in an earlier study17. Separate linear relationships were estimated for underweight (BMI < 18.5), normal weight (BMI > 18.5 to <25) and overweight (BMI ≥ 25 to <30), given observed effect modification by baseline BMI status17. Because individuals with obesity were excluded in these previous analyses, we used the risk estimate for individuals with overweight for individuals with obesity, which could underestimate the full effects of SSB on weight change.
To assess the BMI-mediated effects of SSB intake on incidence, mortality and DALYs of T2D, ischemic heart disease and ischemic stroke, we first calculated the monotonic effect of SSB intake on BMI change for each population stratum by weighting the baseline BMI-specific effect by the respective prevalence of underweight, normal weight and overweight (including obesity) within each stratum. We obtained overweight and underweight population distributions from the NCD-RisC71 and calculated the prevalence of normal weight as 1 minus the sum of these prevalences71. The NCD-RisC estimates go up to 2016, and thus, for our 2020 analysis, we used data from 2016 as a proxy for 2020. Given increasing adiposity globally, this assumption could result in underestimation of disease burdens due to SSBs in 2020. We assumed that individuals with underweight did not experience increased risk of T2D, ischemic heart disease or ischemic stroke with increased consumption of SSBs. As such, the monotonic effect for this population segment was set at 0:
$$\begin{array}{l}{\text{SSB}}-{\text{to}}-{\text{BMI}} {\text{effect}}={\beta }_{\rm{BMI}\ge 25}\,\times \,\left({\rm{overweight}}\; {\text{prevalence}}\right)+\,{\beta }_{{\rm{BMI}}18.5-25}\,\\\qquad\qquad\qquad\qquad\qquad\times \,\left({\rm{normal}}\; {\text{weight}}\; {\text{prevalence}}\right)+0\,\\\qquad\qquad\qquad\qquad\qquad\times \,\left({\rm{underweight}}\; {\text{prevalence}}\right)\end{array}$$
We then estimated the BMI-mediated log(RR) by multiplying the log(RR) per unit increase in BMI and the SSB-to-BMI effect (associated increase in BMI per one-unit-associated increase in SSB intake).
Quantification of uncertainty using Monte Carlo simulations
We used Monte Carlo simulations to quantify the uncertainty around the PAF estimate. In this calculation, we incorporated uncertainty of multiple key parameters, including the usual intake distribution of SSBs in each stratum; underlying T2D, CVD and DALY burden estimates in each stratum; the etiologic estimates (RR) for SSB–BMI, SSB–T2D and SSB–CVD relationships; and the prevalence of individuals with underweight, normal weight or overweight in each stratum. For each SSB–disease combination and stratum, we drew randomly 1,000 times from the respective probability distributions. This included drawing randomly from the normal distribution of the estimate of disease-specific changes in the log(RR) of BMI-mediated and direct etiologic effects for a one-unit increase in SSB intake, the posterior distributions for shape and rate parameters for usual dietary intake and the normal distribution of the estimate for the prevalence of underweight, normal weight and overweight. Draws of proportions that were less than 0 or greater than 1 were truncated at 0 or 1, respectively, and draws of mean intake that were 0 or less were truncated at 0.00001. Each set of random draws was used to calculate the PAFs and, multiplied by the stratum-specific disease rates, the associated absolute attributable disease burden. Corresponding 95% UIs were derived from the 2.5th and 97.5th percentiles of 1,000 estimated models.
Sociodemographic development index
We assessed national-level findings by SDI in 1990 and 2020. The SDI is a composite measure of a nation’s development based on factors such as income per capita, educational attainment and fertility rates18.
Changes in SSB-attributable burdens over time
To compare estimates across different years (1990 and 2020), we calculated differences for absolute and proportional burdens from 1990 to 2020 (that is, 2020 minus 1990). We performed this calculation for each simulation resulting in a distribution of differences, and we report the median and 95% UIs for each difference. We did not formally standardize comparisons over time by age or sex. This decision was made to ensure that findings would reflect the actual population differences in attributable burdens that are relevant to policy decisions. However, we also performed analyses stratified by age and sex, taking into account changes in these demographics over time. All analyses were conducted using R statistical software, R version 4.4.0 (ref. 123) on the Tufts High Performance Cluster.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
