
Table of Contents
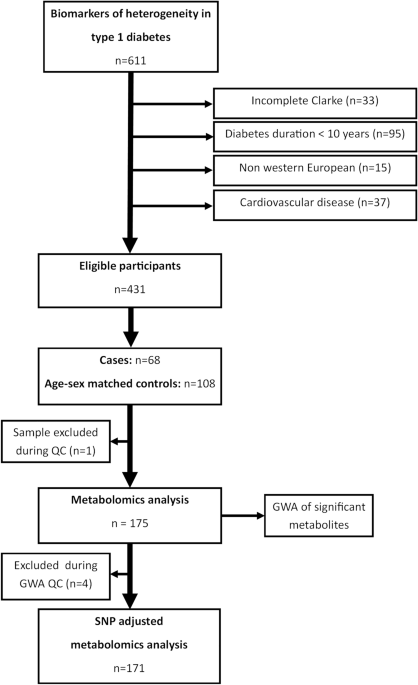
In this nested case-control study, we compared the metabolite profiles of individuals with type 1 diabetes and hypoglycemia awareness to sex- and age-matched controls with type 1 diabetes but without hypoglycemia awareness. (Figure 1). Subsequently, a genome-wide association study (GWAS) of the most important metabolites was performed. We then reintroduced the significant SNPs from his GWAS of metabolites into the analysis of metabolite profiles between individuals with and without her IAH as covariates.
Flowchart of participant inclusion and exclusion and analysis.
participant
Cases and controls were selected from the Dutch Type 1 Diabetes Biomarker Study (NCT04977635) conducted from 2015 to 2021 at Groningen University Medical Center, Diabetes Hospital, Haaglanden Medical Center, and Ikajia Hospital.We previously described this cohort in detail12. Briefly, patients with type 1 diabetes who were 16 years of age or older and had diabetes for more than 5 years underwent extensive evaluation and were prospectively followed between 2015 and 2021. Baseline, 1- and 2-year follow-up, blood and urine samples, physical measurements, and standardized questionnaires were completed. This study used data collected during the baseline visit.
This study was approved by the Medical Ethics Review Board of the Groningen University Medical Center in Groningen, the Netherlands. Informed consent was obtained from all participants in accordance with the Declaration of Helsinki.
Individuals who responded to Clark’s questionnaire, which was validated in the Dutch Clamp, were included13 They were Western Europeans, as determined by self-report or parental place of birth. Because IAH is more prevalent in people with longer diabetes duration, the exclusion criterion was diabetes duration less than 10 years. Additionally, patients with cardiovascular disease, defined as the presence of myocardial infarction, cerebrovascular accident or transient ischemic attack, and peripheral arterial disease were excluded as they are known to influence the metabolic profile. .14.
The presence or absence of impaired consciousness due to hypoglycemia was determined by a score of 3 or higher on the Clarke questionnaire (maximum score = 5). Cases were matched to sex- and age-matched controls using the MatchIt package in R using nearest neighbor matching at a ratio of 1:1.6.
Metabolite quantification
If possible, blood samples were collected into a 10 ml EDTA BD Vacutainer after an overnight fast. Whether a sample was fasted was determined by self-report during the study visit. Samples were centrifuged at 1300 g for 10 min, and the supernatant was divided into 2 ml tubes and stored at −80 °C until use. Serum samples selected for analysis were transported on dry ice to the Helmholtz Institute and further stored at −80 °C until thawed for analysis. Using these reference plasma samples, the long-term stability of plasma metabolites during storage at −80 °C and the performance of the p180 assay have been previously evaluated.15.
Targeted metabolomics measurements were performed using liquid chromatography and flow injection electrospray ionization tandem mass spectrometry (LC and FIA-ESI-MS/MS) and absolute mass spectrometry.IDQ p180 kit (BIOCRATES Life Sciences AG, Innsbruck, Austria). This assay allows simultaneous quantification of 188 metabolites from plasma or serum.The complete assay procedure has been previously published16. Briefly, 10 μL of serum sample was placed into the cavity of a 96-well filter plate for p180 assay and dried for 30 min in a nitrogen stream. Amino acids and biogenic amines were derivatized using an excess of 5% phenylisothiocyanate for 20 min, followed by a drying step. Samples were extracted with 300 μL of methanol containing 5 mM ammonium acetate for 30 min at room temperature. LC runs were performed using an Agilent XDB-C18 column (3 × 100 mm, 3.5 µm). Sample handling was performed by a Hamilton Microlab STAR robot (Hamilton Bonaduz AG, Bonaduz, Switzerland) and an Ultravap nitrogen evaporator (Porvair Sciences, Leatherhead, UK), in addition to standard laboratory equipment. Mass spectrometry was controlled by a 1260 series HPLC (Agilent Technologies Deutschland GmbH, Böblingen, Germany) and an HTC-xc PAL autosampler (CTC Analytics, Zwingen, Switzerland) with the software Analyst 1.6.2. In the LC part, compounds were identified and quantified based on scheduled multiple reaction monitoring measurements (sMRM), and in the FIA part, they were determined based on MRM. Data evaluation and quality assessment for quantification of metabolite concentrations were performed using the software MultiQuant 3.0.1 (SCIEX) and Met.IDQ Software packages that are an integral part of AbsoluteIDQ kit. Metabolite concentrations were calculated using internal standards and reported in μmol/L (μM).
In addition to the study samples, five aliquots of pooled human reference plasma were analyzed on each kit plate.
Metabolite quality control and normalization
Metabolites in assays with more than 40% missing data were excluded from the analysis. Missing data for metabolite concentrations <40% were imputed using a random permutation algorithm using the minimum value specified by the kit's limit of detection (LOD) divided by the square root of 2. Additionally, metabolites with coefficients of variation >25% were considered unreliable and excluded from the analysis.
Batch normalization was performed by calculating the plate average for each metabolite and then using these averages to calculate the overall average of the three plates. The overall mean divided by the plate mean was used to calculate plate coefficients, and these plate coefficients were used as normalization factors for each plate and metabolite. These normalized values were used for further analysis.
Genotyping, quality control, and imputation
Samples collected during baseline measurements were separated and genotyped using Infinium GSA Array 24 chips v1 and v3 Illumina Inc. (San Diego, USA). Samples that did not meet the following quality control criteria were excluded: sample call rate < 0.95, SNP call rate < 0.96, MAF < 0.01、性染色体のヘテロ接合性 (0.2 ~ 0.8)、系統による同一性 > 0.185, and samples with heterozygosity greater or less than the mean ± 3 SD.
Imputation was performed using the Michigan Imputation Server’s Minimac4 tool and imputed to Haplotype Reference Consortium version 1.1.17. Data was phased using Eagle v2.4 using the HRC1.1 2016 hg (GRCh37/hg19) reference panel.After imputation, MAF < 0.05, variant with imputation quality score R2 < 0.5, and HWE p-value < 10–12Filtered.
statistical analysis
Descriptive statistics were performed using R statistical software. Population characteristics are expressed as means with standard deviations, medians with first and third quartiles, and numbers with percentages. Statistical differences between those with and without IAH were analyzed using either the Student t test, Mann-Whitney U test, and chi-square test as appropriate.
A total of 153 metabolite compounds and 25 metabolite sums and ratios passed quality control and were included in the analysis. All analyzes were performed using MetaboAnalyst 5.0.18. Data were first normalized by subtracting the median, transformed using a log base of 10, and scaled using Pareto scaling.19. Differential expression was calculated by log2 fold change. Differences in metabolite abundance between NAH and IAH were analyzed using the MetaboAnalyst 5.0 platform18. Linear models were fit for each metabolite adjusting for gender, diabetes duration, and fasting blood glucose level. Missing covariate data were replaced with the population mean. Duration of diabetes was used as a covariate instead of age. These two variables are strongly correlated and the duration of diabetes is clinically more relevant as a risk factor for IAH. Additionally, a sensitivity analysis was performed excluding data from individuals with c-peptide > 300 pmol/L and using antihypertensive or lipid-lowering drugs.
Genome-wide association models were performed using PLINK 2.0. Linear models adjusted for sex and age were fitted using the entire sample population for each significant metabolite. Data were visualized in Manhattan and QQ plots for each metabolite tested. We also assessed whether previously reported SNPs were significantly associated with specific metabolites in these participants.
In the second metabolite analysis, genome-wide significant SNPs were introduced as covariates in a linear model along with age, diabetes duration, and fasting blood glucose. Metabolites that remain significant after adjusting for SNPs may be associated with IAH even though SNP variation is associated with higher or lower concentrations of the metabolite.
Metabolites that reached an unadjusted p value < 0.05 were searched in the Small Molecule Pathway Database (SMPDB) and manually searched in the literature.
