
Table of Contents
data
All data utilized in this study were obtained from the UK Biobank, a comprehensive biomedical database containing extensive health information for 502,625 people living in the UK. Baseline assessments were conducted between 2006 and 2010 with participants aged 40 to 69 using a combination of touchscreen questionnaires, nurse-led interviews, and various tests and measurements. Information on dietary habits was collected using a food frequency questionnaire that has been shown to reliably rank participants according to their intake of major food groups.9. Participants’ physical activity levels were assessed using an adapted version of the International Physical Activity Questionnaire (IPAQ).Ten. During the oral interview, participants were asked about various aspects of their personal history and medical history, including childhood factors, employment status, medical conditions, medications, and past surgeries. Physical measurements performed during the baseline assessment include blood pressure, arteriosclerosis, bone density, grip strength, hearing tests, eye measurements, and spirometry. Thirty blood analyzes selected based on established risk factors for disease or diagnostic measures were collected along with eight urine analyses.
result
The primary endpoint of this study was the incidence of type 2 diabetes within 10 years of baseline assessment (3650 days). To determine this outcome, we utilized the UK Biobank ‘first occurrence’ category. This category contains two data fields for each three-letter ICD-10 mapped code. The first field represents the date when the ICD code was first reported, and the second field contains the source where the code was first recorded. Sources of information include reading code information from primary care data, his ICD-9 and ICD-10 codes from hospital inpatient data, his ICD-10 codes from death register records, and his ICD-10 codes from his subsequent visits to the UK Biobank Assessment Center. Contains self-reported medical condition codes reported. . In this study, the outcome variable was defined as his report of ICD code E11 (non-insulin-dependent diabetes) during the 10-year study period.
Exclusion criteria
Individuals who had diabetes at baseline were excluded from the study. Specifically, regardless of the type of diabetes, those who self-reported having diabetes at the baseline interview, had an HbA1c measurement >48 mmol/mol, or had a diagnosis of diabetes recorded in their hospital or primary care records. Targeted people are those who are However, women who had diabetes only during pregnancy were not excluded. In addition, participants who were lost to 3650 days of follow-up due to death or withdrawal of consent were also excluded from the study.
Variable selection
Our variable selection approach was purposeful and based on expert judgment. From the beginning, our primary objective was to preserve as much information as possible to facilitate detailed and unbiased analysis about our participants. With this objective in mind, we committed to using only baseline data for predictive modeling and began by excluding variables collected after the baseline assessment. The baseline data was then carefully evaluated to ensure its relevance and accuracy. This assessment was a manual process in which each variable was assessed for its contribution to a comprehensive understanding of the participants’ health, lifestyle, and socio-economic status. Only variables that were deemed irrelevant to these important areas or that did not provide additional insight were set aside. For example, data attributes such as measurement device serial number, test duration, and reasons for skipping certain tests were ignored because they did not convey meaningful information about the participants. In situations where overlapping variables were present, such as when a participant’s blood pressure was measured on two separate occasions, the values were averaged and expressed as a single variable. Following this, we identified 111 variables with 70% or more missing observations and these were removed from the dataset. To increase the informative value of the dataset, certain variables that were missing from the UK Biobank were created using available data. This includes creating variables such as estimated glomerular filtration rate (eGFR), total weekly alcohol intake, pulse pressure, and mean arterial pressure. Additionally, information about first-degree relatives with type 2 diabetes was summarized into a score ranging from 0 to 2 depending on the number of relatives with diabetes (2 means that the number of relatives with diabetes is her 2nd degree). (indicates more than one person). After this careful selection and refinement process, our dataset consisted of 419 variables considered most suitable for model development. A comprehensive list of these variables, as well as formulas for creating new variables, is provided in a separate document (Supplementary).
model development
The classification model used in this study employs the Extreme Gradient Boosting (XGBoost) algorithm, which is a widely used ensemble learning technique.11. XGBoost is known for its high prediction accuracy and computational efficiency, making it a popular choice for classification and regression tasks.12, 13. The first step in the analysis was to split the data into two sets: a training dataset and a validation dataset. The training set contained 80% of the total observations, and the remaining 20% was assigned to the validation set. Splits were stratified based on the outcome variable to ensure that the proportion of individuals with the outcome of interest was balanced in both sets. Once the splitting was complete, the training dataset underwent additional preprocessing. All categorical features were converted to numerical variables using one-hot encoding. Variables with very low variance were identified and removed to increase model stability. In particular, to address class imbalance in the training data, the majority of classes were downsampled to achieve his 1:3 ratio. This downsampling was only applied to the training set.
Certain preprocessing steps, such as one-hot encoding and distributed filtering, were learned from the training data, but the transformations were applied consistently to both the training and validation sets. However, the downsampling step was only applied to the training data and did not affect the validation dataset.
Hyperparameter tuning
Latin hypercube sampling is a method that produces a set of parameter values that are evenly distributed throughout the parameter space. This method can be used for hyperparameter tuning in machine learning to efficiently explore the optimal combination of hyperparameters.14. The grid search algorithm requires defining a grid of hyperparameters to test, whereas the Latin hypercube sampling method randomly selects hyperparameter values within a defined range. The 5-fold cross-validation technique splits the data into 5 subsets, trains the model on 4 subsets, tests on the 5th subset, and repeats this process 5 times. The average performance over all iterations is used as the evaluation metric. The tuned hyperparameters include the number of variables randomly sampled as candidates in each split (mtry), the number of trees (tree), the minimum node size (min_n), the tree depth (tree depth), Includes the required minimum loss reduction. Creating more partitions at leaf nodes (loss reduction) and the percentage of samples used to train each tree (sample size). The objective was to find the hyperparameter combination that yields the best area under the receiver operating characteristic curve (ROC-AUC).
Model evaluation
The main performance metric was ROC-AUC, but due to reliability in unbalanced datasets13,14, also provided a comprehensive set of other indicators for transparency. These include accuracy, sensitivity, specificity, precision, F1 measure, PR-AUC, and confusion matrix. To quantify the uncertainty in model evaluation, 95% confidence intervals were calculated for all performance metrics using bootstrapping with 1000 replications. All evaluations were performed on a validation dataset that was excluded from model training.
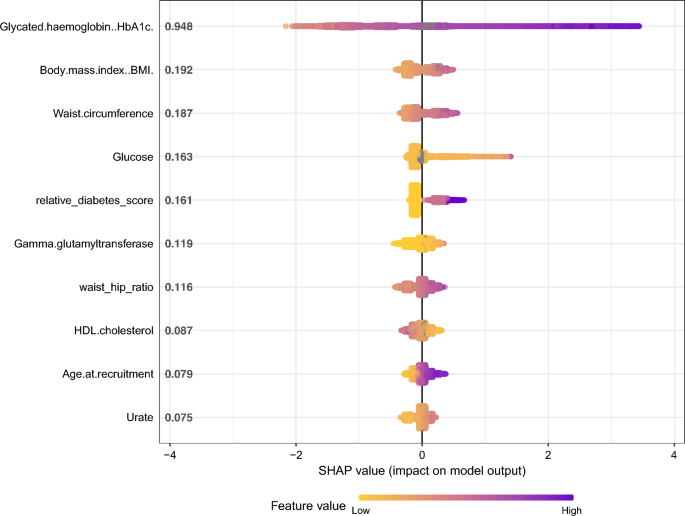
Shapley value (model interpretability and feature importance)
SHapley Additive Explanation (Shap) is a technique used to explain predictions made by machine learning models.15,16. It comes from cooperative game theory and is based on the concept of Shapley values. A feature’s Shap value is the average marginal contribution of that feature to the model’s predictions after considering all possible combinations of features. To calculate the sharpness value, the influence of a feature on the model’s predictions is compared with and without that feature. This provides a measure of a feature’s importance, taking into account its interactions with other features. The Shap method can be used for both local interpretability to understand individual predictions and global interpretability to identify drivers of predictions across datasets. In this study, only global interpretive tools were used.
Models with selected features
The main model contained 419 features, and the top 10 features with the highest predictive value were identified using the Shap value. The reduced XGBoost model was developed using the same training/validation split, feature preprocessing, and hyperparameter tuning as the main model. The performance of both the main and reduced models was compared based on their predictive ability using various metrics such as ROC-AUC, accuracy, sensitivity, and specificity.
Gender model
To compare important predictors of diabetes separately for women and men, we constructed two additional models by dividing the total population by sex. We then used the Shap summary graph to illustrate her 10 most important predictors for each gender. The development of these models followed the same steps as the main model, except for adding gender-specific factors that were not included in the main model. For the female cohort, 30 factors related to menstruation, pregnancy, childbirth, menopause, and use of hormone replacement therapy were included. For the male cohort, additional characteristics include relative age of first beard, relative age of voice break, pattern of scalp hair/baldness, and number of children fathered.
All data preparation and model engineering was performed using R and RStudio Workbench version 1.4.1717-3.Tidymodels framework was used to build the model17.
Ethics approval
This study complies with the ethical standards of the Swedish Ethical Review Authority, which approved the research methods and confirmed compliance with relevant ethical principles and guidelines. All procedures involving human participants were performed in accordance with the Declaration of Helsinki and relevant guidelines/regulations. UK Biobank obtained written informed consent from all participants before participating in the study and ensured that all methods were conducted in accordance with the aforementioned ethical standards.
